
List of NixOS series posts:
Right now, I'm gradually migrating my servers from Devuan Linux to
NixOS. NixOS is a Linux distribution centered on a set of
Nix configuration files located in /etc/nixos, which is used to install and
configure the whole operating system. Because this configuration set defines
ALL config files and packages on the system, as long as you use the same
config files, you will absolutely get the same operating system every time you
reinstall. Nix configuration language is also Turing complete, so you will be
able to generate config files with Nix, no matter how complicated that software
is.
Another important feature of the Nix package manager is reproducible builds. Every package in NixOS is defined with Nix config files, and the Nix package manager can promise that, as long as the software doesn't deliberately fight back, you will get binaries with the exact same functionality, and in most cases, get binaries with the same hash values (such as MD5 and SHA256).
Since NixOS the Linux distribution is quite unfriendly to beginners, I will write a series of posts on my whole transition process. This is the first post in the series and mainly focuses on the reason I fall in love with it.
Before I use NixOS
Managing Multiple Servers
How many servers do you have? I have 10. In addition to the 4 VPSes listed on my DN42 Peering Page, which I run my website and BGP network on, I also have 1 dedicated server for my CI and backups, 3 Oracle cloud servers that I got for free, 1 VPS with large RAM from VirMach New York that I use to run Java apps like Keycloak, and 1 VPS planned to replace the Virtono node in Frankfurt, Germany.
When you have that many servers, you will find managing all of them be difficult. If I want to edit the BIRD config on all my nodes, I will have to do:
# Pull the config from a random node
scp hostdare.lantian.pub:/etc/bird/bird.conf .
# Edit the config
nano bird.conf
# Push the new config to all nodes with Ansible, and tell BIRD to reload
ansible all -m copy -a "src=bird.conf dest=/etc/bird"
ansible all -m shell -a "birdc configure"And this is the most trivial scenario. Things are more troublesome when the config file is supposed to be different on all my nodes. In this case, I have to log in to each node and do the config change manually. Half an hour would have passed for some config changes on all 10 nodes.
As an attempt to resolve this problem, earlier this year I started to generate the config files with Ansible's template module. This is one of my BIRD config files for example:
define LTNET_IPv4 = {{ ltnet_prefix_v4 }}.1;
define LTNET_IPv6 = {{ ltnet_prefix_v6 }}::1;
define LTNET_AS = {{ 4225470000 + ltnet_index }};With this, I can define variables for each node in the Ansible inventory, and generate the config files automatically:
all:
hosts:
hostdare.lantian.pub:
ltnet_index: 3
ltnet_prefix_v4: 172.18.3
ltnet_prefix_v6: fdbc:f9dc:67ad:3Once I finished changing the config, I simply ran ansible-playbook to call my
predefined playbook to automatically generate new configs onto every node and
reload BIRD. This resolves the issue for managing BIRD config, but I have more
pieces of components that require similar work, like Nginx, CoreDNS, Tinc VPS,
etc. In addition, the configuration of the system itself, from the list of
preinstalled packages to sysctl.conf and motd, needs dedicated playbooks.
Now I have bunches of playbooks and bunches of templates.
That's not the end of the story. Apparently, I cannot rerun each and every playbook when I'm changing something, or it would take several hours. Therefore, I need to determine which playbooks I should call manually. Since I have a LOT of playbooks, I've had several oops where I cannot see the changes from my config update, and it ended to be using the wrong playbooks.
We're still not done yet. My nodes can be unstable sometimes, making deployments fail, as they are cheap VPSes anyway. When this happens, I usually wait until that node recovers and rerun the deployment. Only if I still remember to do it, that is. If I forgot to deploy my last config change and my new change happened to rely on that, some more time would be spent diagnosing the issue.
Distributing Binaries
I have a lot of software that I developed or modified myself, like my modified Nginx, Traceroute poet, BIRD Looking Glass, and my customized slimmed-down kernel. Apparently, I cannot compile them on my cheap VPSes, or my provider may shut them down for excessive CPU usage and GG. I need to compile the software somewhere and then deploy them to all the nodes.
Before I switch to NixOS, I use the Devuan Linux distro (basically Debian without SystemD). Debian is infamous for the complexity of packaging software, as you need to write a complicated Makefile just for packaging into DEB files. In addition, complicated programs may depend on lots of customized libraries. For example, my Nginx depends on Brotli, Zlib modified by Cloudflare, BoringSSL, and a bunch of third-party Nginx modules. This makes it even harder to pack everything into one DEB file. Therefore, I simply gave up on DEB packages and started to search for better solutions.
The next solution is Docker containers. Docker containers are really easy to
use,
I started with them back in 2016.
However, with continuous version updates and the addition of new features, the
memory consumption of Docker is rising as well. dockerd usually takes 80-100MB
RAM on my nodes, and that's not counting another 20-30MB from containerd. For
my small VPS boxes with only 512MB RAM, that's almost one-fourth of my total RAM
allotment.
RAM usage is also the main reason I switched from Debian to Devuan. The various processes of SystemD took some 50MB of RAM, but since Devuan is still using the sysvinit framework from Debian 7 and earlier, the resident memory usage of
init,udevandrsyslogadds up to only 20MB. And as I have Docker, I don't need the advanced features of SystemD anyway.If I ever ran out of RAM on these small VPS boxes, it can get anywhere from being terribly slow due to bad IO performance and slow SWAP operations, to being completely frozen for high IO latency or being shut down for excessive IOPS.
There is a replacement for dockerd, of course, the Podman developed by Red
Hat. Podman's largest difference is that it doesn't have a residual background
process like dockerd, and it only creates one or two processes for each
running container for monitoring, logging, and DNS resolution purposes. However,
lacking a background process means no autostart on system bootup, and Podman
relies on an external process manager like SystemD or Supervisord to do that. In
addition, while Podman strives to emulate the Docker API, the compatibility work
is still far from complete, and it is hard to use tools like Docker Compose with
it. For me, the biggest no-go is the lack of
IPv6 NAT, which basically means
no IPv6 connectivity in my containers, and no access to services in containers
from the IPv6 network.
This leads to the next problem: container networking is hard. By default, Docker
containers get their own network namespaces with their own IP addresses. This
means that containers cannot access each other from 127.0.0.1 (localhost).
Instead, they need to resolve the names via DNS. For example, PHP-FPM sitting in
a container cannot connect to a MySQL database via 127.0.0.1. It has to
resolve the IP of the container mysql with DNS before it can make a
connection. Now, programs in containers cannot only listen on 127.0.0.1. They
need to listen on 0.0.0.0 instead so that the host and other containers can
access it. Since databases like MySQL usually default to listening on
127.0.0.1 for security, some extra config changes are needed either when
packing the Docker image or using it.
DNS resolution causes new issues as well. Programs may not refresh their DNS
cache in time, with one major example being Nginx. For example, I have two
containers, A (172.17.0.100) and B (172.17.0.101). I changed their config
and redeployed them with docker-compose. Since docker-compose creates the
containers in parallel with no deterministic order, A gets 172.17.0.101 this
time, and B gets 172.17.0.100. Since Nginx doesn't refresh DNS resolution
results in time, whenever I try to access A, I actually get to B, and vice
versa. To avoid this issue, I have to restart all containers related to A and B,
and this is some extra maintenance cost.
Yes, you can actually resolve this with Docker: you can set the networking mode
of containers to host (aka --net host) to let the containers share the
network namespace and IPs with the host. But remember that Docker containers
usually listen on 0.0.0.0? Many Docker images had already changed the config
for you to listen on 0.0.0.0, and as you use host mode, you're exposing the
port to the public Internet, causing a security risk. Now you need to change the
config back to what it was. Too much trouble!
Another way that would have worked is manually assigning an IP to each container, so that each of them gets the same IP after recreate. For obvious reasons, manually assigning IPs to dozens of containers isn't fun.
Fixing System Crashes
Since I change my system config from time to time, it's common for me to accidentally kill the network or kill the kernel at the initrd boot stage. Whenever this happens, I will have to use a slow VNC console, or even some IPMI that supports only Java 7, to change the config back. If I'm even less lucky and the system doesn't boot at all, I will need to fix that in a rescue system.
Rescue systems from different providers vary, and you will encounter strange issues. I've had a rescue system with kernel 4.9 not recognizing my Zstd-compressed Btrfs filesystem, and another rescue system not providing kernel headers, making it impossible to compile ZFS kernel modules and load my ZFS partition.
In addition, you are lucky if you nailed it on your first attempt. As I don't reboot my nodes often, the boot failure I'm dealing with may be caused by some change 3 months ago. Therefore, I have to check my Git history and guess the cause while I repeatedly boot to the rescue system, mount my partitions and change the config, and reboot back to the hard drive, praying it will work this time.
The day would have passed once I finally fixed the problem.
Installing NixOS
The unique Nix package/config management system resolves all the issues above. Let's start by installing NixOS first. Since NixOS is a distro based on config files, the installation process comes down to 3 steps:
- Partition the disk and mount to
/mnt. Anyone who has installed Arch Linux or Gentoo already knows what to do. - Generate a default config and make some changes.
nixos-generate-config --root /mntwill autodetect your hardware and create a config at/mnt/etc/nixos/configuration.nix。 - Install your system based on the config file with
nixos-install。
The installation manual of NixOS is on this page, and its ISO images can be downloaded on this page.
If you want to install NixOS on a VPS, but your provider cannot mount an ISO for you, and your VPS is too low on RAM to boot the NixOS installation image from the network (Netboot.xyz), you can also use NixOS-Infect to replace your existing system with NixOS.
NixOS-Infect automatically mounts a Swap file on servers with low RAM to avoid memory exhaustion during the installation process. But if you use Btrfs, ZFS, or any filesystem that doesn't support mounting a Swapfile, you need to comment out the
makeSwapandremoveSwapfunctions from thenixos-infectscript.
Managing Multiple Servers, but with NixOS
At the very beginning, I mentioned that one important feature of NixOS is
managing each and every package and config with a set of Nix config files.
Therefore, we can use any tools we like, for example Ansible, Rsync, or even
Git, to manage the config at /etc/nixos. Since this is the only config file we
care about, we no longer need a bunch of complicated Ansible playbooks or dozens
of Rsync commands. We only need to overwrite /etc/nixos, run
nixos-rebuild switch, and call it a day.
Since each config update is equivalent to overwriting all programs and config in the whole system, you don't need to decide on which special script to use, which services to reboot, and which config files you forgot to copy onto the node. NixOS will automatically compare your new config to the last one and restart the services on demand.
NixOS, as a Linux distro with some history, also has some software ecosystem around it, like the Deploy-RS tool. It can read your Nix Flakes config file (a variation of Nix config file), compute the result on your local machine, and copy it to all your nodes and activate it.
Binary Distribution, but with Nix Package Manager
The Nix package manager stores binaries in paths like
/nix/store/wadmyilr414n7bimxysbny876i2vlm5r-bash-5.1-p8. The hash value at the
middle corresponds to all inputs from the package config, including the version
of the source code (like URLs to tar.gz, Git commit hashes, etc.), SHA256 of
the source code, compilation and installation commands, and versions of all
libraries it depends on. To make sure the software is exactly the same, Nix
compiles them in a sandbox. Compilation scripts in the sandbox can only access
the dependent libraries. It cannot even get the system time (fixed to UNIX
timestamp 0 or 1970-01-01 00:00:00) or connect to the Internet.
Let's take an example. It's well known that most programs on Linux depends on the system Libc. Let's find out which Libc the bash we're talking about is depending on:
$ ldd /nix/store/wadmyilr414n7bimxysbny876i2vlm5r-bash-5.1-p8/bin/bash
linux-vdso.so.1 (0x00007ffe169d8000)
libdl.so.2 => /nix/store/mij848h2x5wiqkwhg027byvmf9x3gx7y-glibc-2.33-50/lib/libdl.so.2 (0x00007f767f863000)
libc.so.6 => /nix/store/mij848h2x5wiqkwhg027byvmf9x3gx7y-glibc-2.33-50/lib/libc.so.6 (0x00007f767f69e000)
/nix/store/mij848h2x5wiqkwhg027byvmf9x3gx7y-glibc-2.33-50/lib/ld-linux-x86-64.so.2 => /usr/lib64/ld-linux-x86-64.so.2 (0x00007f767f86a000)This Bash can only use a Glibc in a fixed location in /nix/store, or the exact
copy used during compilation. Therefore, the Nix package manager also avoids
program crashing due to shared library updates. Since programs can only use the
libraries at exact paths, and an exact path with config hash must correspond to
the exact library, as long as a programs works during compile time, it will
continue to work exactly that way.
This doesn't include cases where the program has deliberate countermeasures, like generating compilation results from
/dev/random, or behaving differently based on system time (aka time bomb). However, these behaviors are extremely rare in normal programs, so for the vast majority of programs, the Nix package management system can fulfill its promise.
Likewise, If I copy this Bash and its dependent libraries to another system, as long as the path is still the same, this Bash program will surely work the same. Therefore, there is a version of the Nix package manager that installs onto other distros like Ubuntu or Arch Linux, which shares most binaries with NixOS and have the same functionality without interfering with the system's own package management.
That is exactly what the Deploy-RS tool
mentioned above is based on. It downloads or builds all packages locally and
then copies the results from /nix/stores onto the target nodes, so no
compilations are necessary on the target nodes.
By the way, the Nix package manager treats config files in the same fashion as
packages. For example, /nix/store/dpgmxhxkf55dfgwnrhz7hc4ahckkx78b-nginx.conf
is my Nginx config file. Deploy-RS uses the same logic to generate the config
files locally, then copy them to the remote server.
Fixing System Crashes, but Luckily with NixOS
Since all binaries of NixOS are stored in /nix/store and there is no unified
path, NixOS will adjust the PATH environment variable to include all bin
folders of packages, so you can call them directly in Bash; In addition, NixOS
will link some config files to /etc so programs can find them at their desired
location.
If the new config files crashed the system, theoretically, you only need to
adjust PATH and links in /etc to recover to the last correct config, and the
system will recover to an older state. Therefore, NixOS directly provides the
options in its boot menu, so you can boot to a specific deployment state:
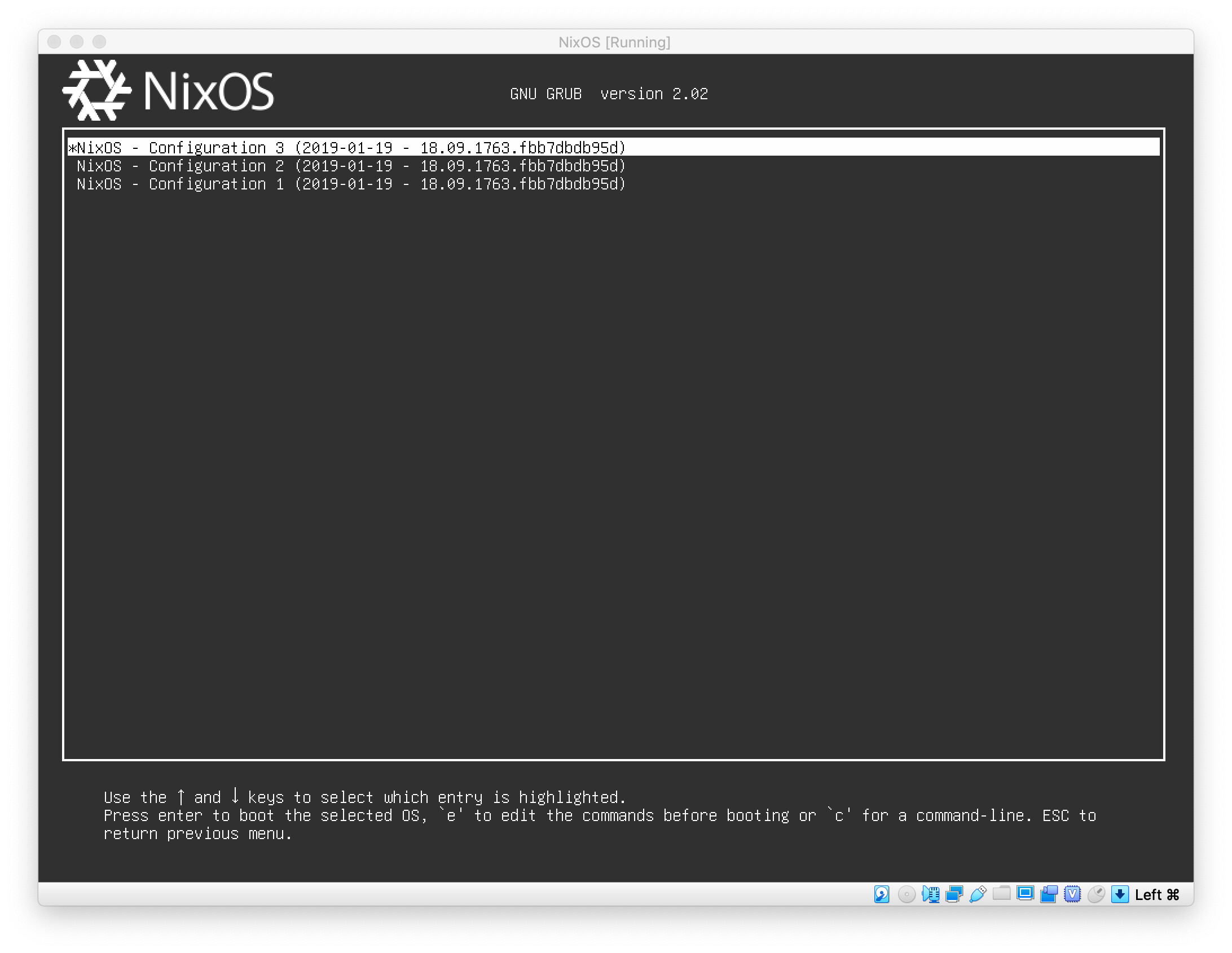
Image downloaded from https://discourse.nixos.org/t/how-to-make-uefis-grub2-menu-the-same-as-bioss-one/10074
Therefore, NixOS doesn't need a rescue system in most cases, as it can recover itself with an older config state. Once the system is up, you can proceed to redeploy the fixed config or continue to use the older system as if nothing has happened.
Note that this NixOS mechanism is not a filesystem snapshot and cannot rollback data files of programs.
Assuming that I upgraded to MariaDB 10.6 and rolled back to an older config with MariaDB 10.5. Since MariaDB 10.6 auto-upgraded the data files, MariaDB 10.5 wouldn't recognize them and will refuse to start. NixOS cannot and does not intend to fix the issue.
Conclusion and Followups
This post mainly focuses on introducing the advantages of NixOS and its package management system over other Linux distros. In the follow-up posts, I will explain the process of configuring everything in NixOS and replacing my nodes step by step.