前言 SideStore 是一款常用的 iOS 应用侧载工具,可以绕过 App Store 安装第三方应用。它的工作原理是用你的 Apple ID 获取免费的苹果开发者证书,给你要安装的应用签名,从而让应用可以在 iOS 设备上正常运行。 然而,苹果为了维护其对 iOS 生态系统的控制,阻止第三方应用商店使用开发者证书大规模地绕过限制,对开发者证书设置了 7 天的过期时间。用户需要定期获取新的开发者证书,重新给应用签名,才能一直使用自己安装的第三方应用。 传统的侧载工具,例如 AltStore,都依赖电脑上的 iTunes 等软件进行重新签名的操作。但 SideStore 与其它侧载工具不同,它只有首次安装时需要电脑辅助。安装完成后,SideStore 可以自己模拟一台安装了 iTunes 的电脑,让 iOS 系统通过虚拟网络与其通信,从而实现无需电脑就能给应用重新签名,甚至安装新的第三方应用的效果。 SideStore 的虚拟网络一般可以用下面两种方式实现: WireGuard:...

从零开始实现 Nix 对数函数库
从零开始实现 Nix 数学库 系列文章目录: 从零开始实现 Nix 三角函数库 从零开始实现 Nix 对数函数库 (当前文章) (题图来自: 维基百科 - 对数 ) 起因 由于一个有点离谱的原因(计算 VPS 间的物理距离来估算网络延迟),我 用 Nix 实现了一个有点离谱的三角函数库 。我把三角函数库 发布到 GitHub 上 后,发现居然有人用!看来我的需求也不算太离谱。 在仓库的 Issues 里, 有用户建议我给这个数学库添加一些指数/对数函数支持 ,例如 exp , ln , pow 和 log 。 因为从零开始实现这些基础函数也挺有趣的,所以我就抽空研究了一下。这四个函数中,有些难度的是 exp 和 ln 。 pow 和 log 都可以用另外两个函数转化出来: log n x = ln x ln n p o w ( x , n ) = x n = exp ( n ∗ ln x ) \begin{aligned} \log_n x &= \frac{\ln x}{\ln n} \\ pow(x, n) = x^n &= \exp (n * \ln x) \end{aligned} lo g n x p o w ( x , n )...
$100,DIY 搭建合法的 LTE 网络
是的,你没看错,不需要法拉第笼等信号屏蔽措施,只需要大概 100 美元,你就可以在(美国的)家里搭建一个合法的 LTE 网络,可以 24 小时连续发射。 关于「合法」:我不是律师或者无线电专家。根据我对相关政策法规的研究,我的整套配置应当是合法的。但如果你按照本文操作后遇到了法律问题,我不负任何责任。 CBRS 频段:美国的免授权 LTE/5G 频段 自建 LTE 网络的难点不在技术部分,而是在于合法地获取无线电频谱资源。软件方面,早在 2014 年就有了 srsRAN 等基于 SDR(软件定义无线电)的 LTE 发射方案,也有 Magma 、 Open5GS 等开源的核心网软件。 但是在无线电频谱方面,LTE、5G 等移动网络使用的无线电频率都处在授权频段,需要向当地政府的无线电管理机构提出申请,并缴纳昂贵的频段使用费(一般根据覆盖范围和当地人口数)才能合法使用。除非你所在的地方人烟稀少,否则绝大部分爱好者都会被挡在这一步。如果你未经授权就占用频段强行发射,...
用 Nix 编译自定义 Android 内核
前言 我现在使用的手机是 Motorola Edge+ 2023,一台 Android 手机。为了更好的自定义手机的功能,我解锁了手机的 Bootloader,并且获取了 Root 权限,以便安装 LSPosed 以及基于 LSPosed 的各种插件。 我使用的 Root 方案是 KernelSU ,通过修改 Linux 内核,从而允许且只允许指定程序获取 Root 权限。虽然 KernelSU 官方提供了适配大部分手机的 GKI 内核镜像,但我给手机刷了不兼容 GKI 的 LineageOS,所以只能自己编译内核。 由于直接修改内核镜像的难度较大,我们一般是从手机厂商获取以 GPLv2 协议开源的内核源码,按照 KernelSU 的官方教程 进行修改后,再编译成完整的内核。 注:现在有一种新的 Root 方案 APatch ,通过直接修改内核镜像来实现类似 KernelSU 的功能。我没试过 APatch,但如果你不想自己编译内核,可以尝试一下。 由于 KernelSU 使用广泛,有一些开发者编写了 GitHub Actions 的 Workflow,例如 https://github....

NixOS 系列(五):制作小内存 VPS 的 DD 磁盘镜像
NixOS 系列文章目录: NixOS 系列(一):我为什么心动了 NixOS 系列(二):基础配置,Nix Flake,和批量部署 NixOS 系列(三):软件打包,从入门到放弃 NixOS 系列(四):“无状态”操作系统 NixOS 系列(五):制作小内存 VPS 的 DD 磁盘镜像 (当前文章) 黑色星期五已经过了,相信有一些读者新买了一些特价的 VPS、云服务器等,并且想在 VPS 上安装 NixOS。但是由于 NixOS 的知名度不如 CentOS、Debian、Ubuntu 等老牌 Linux 发行版,几乎没有 VPS 服务商提供预装 NixOS 的磁盘镜像,只能由用户使用以下方法之一手动安装: 自行挂载 NixOS 的安装 ISO 镜像,然后手动格盘安装。 由于你可以在 NixOS 安装镜像的环境中随意操作 VPS 的硬盘,这种方法自由度最高,可以任意对硬盘进行分区,指定文件系统格式。但是,使用这种方法前,你的主机商需要在以下三项前提中满足任意一项: 主机商直接提供 NixOS 的 ISO 镜像挂载(即使是很老的版本)...
从零开始实现 Nix 三角函数库
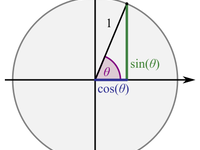
从零开始实现 Nix 数学库 系列文章目录: 从零开始实现 Nix 三角函数库 (当前文章) 从零开始实现 Nix 对数函数库 (题图来自: 维基百科 - 三角函数 ) 起因 我想计算我的所有 VPS 节点之间的网络延迟,并把延迟写入 Bird BGP 服务端的配置中,以便让节点之间的数据转发经过延迟最低的路径。但是,我的节点截至今天有 17 个,我不想在节点之间手动两两 Ping 获取延迟。 于是我想了一种方法:标记所有节点所在物理地点的经纬度,根据经纬度计算物理距离,再将距离除以光速的一半即可获得大致的延迟。我随机抽样了几对节点,发现她们之间的路由都比较直,没有严重的绕路现象,此时物理距离就是一个可以满足我要求的近似值。 因为我的节点上用的都是 NixOS,统一使用 Nix 语言管理配置,所以我需要找到一种在 Nix 中计算这个距离的方法。一种常用的根据经纬度算距离的方法是半正矢公式(Haversine Formula),它将地球近似为一个半径为 6371 公里的球体,...
Optimus MUXed 笔记本上的 NVIDIA 虚拟机显卡直通(2023-05 更新)
一年前,为了能够一边用 Arch Linux 浏览网页、写代码,一边用 Windows 运行游戏等没法在 Linux 上方便地完成的任务, 我试着在我的联想 R720 游戏本上进行了显卡直通 。但是由于那台电脑是 Optimus MUXless 架构(前文有各种架构的介绍),也就是独显没有输出端口、全靠核显显示画面,那套配置的应用受到了很大的阻碍,最后被我放弃。 但是现在,我换了台新电脑。这台电脑的 HDMI 输出接口是直连 NVIDIA 独立显卡的,也就是 Optimus MUXed 架构。在这种架构下,有办法让虚拟机识别到一个「独显上的显示器」,从而正常启用大部分功能。于是,我终于可以配置出一套可以长期使用的显卡直通配置。 更新日志 2023-05-08:针对新版 Looking Glass B6 更新部分内容。 2022-01-26:PCIe 省电补丁实测无效。 准备工作 在按照本文进行操作前,你需要准备好: 一台 Optimus MUXed 架构的笔记本电脑。我的电脑型号是 HP OMEN 17t-ck000(i7-11800H,RTX 3070)。...
NixOS 系列(四):“无状态”操作系统
NixOS 系列文章目录: NixOS 系列(一):我为什么心动了 NixOS 系列(二):基础配置,Nix Flake,和批量部署 NixOS 系列(三):软件打包,从入门到放弃 NixOS 系列(四):“无状态”操作系统 (当前文章) NixOS 系列(五):制作小内存 VPS 的 DD 磁盘镜像 更新记录: 2023-02-18:在「移动 Nix Daemon 的临时文件夹」一段,修正配置不对 root 用户生效的问题。 NixOS 广为人知的一大特点是,系统大部分软件的设置都由 Nix 语言的配置文件统一生成并管理。即使这些软件在运行时修改了自己的配置文件,在下次切换 Nix 配置或者系统重启时,NixOS 也会将配置文件重新覆盖。 例如,在运行 NixOS 的电脑上运行 ls -alh /etc ,可以看到大部分配置文件都只是到 /etc/static 的软链接: # 省略部分不相关的行 lrwxrwxrwx 1 root root 18 Jan 13 03:02 bashrc -> /etc/static/bashrc lrwxrwxrwx 1 root root 18 Jan 13 03:...
NixOS 系列(三):软件打包,从入门到放弃
NixOS 系列文章目录: NixOS 系列(一):我为什么心动了 NixOS 系列(二):基础配置,Nix Flake,和批量部署 NixOS 系列(三):软件打包,从入门到放弃 (当前文章) NixOS 系列(四):“无状态”操作系统 NixOS 系列(五):制作小内存 VPS 的 DD 磁盘镜像 NixOS 的一大特点是,系统所有的二进制程序和库文件都在 /nix/store 目录中,由 Nix 包管理器管理。这也意味着,NixOS 不符合 Linux 的 FHS 标准 ,它的 /lib 或 /lib64 目录下不存在类似 ld-linux-x86-64.so.2 之类的库文件动态加载器,更不存在 libc.so 之类的库文件。因此,除非静态链接,否则为其它 Linux 下编译的二进制文件将完全无法在 NixOS 下运行。 所以,要在 NixOS 上使用尚不存在于 Nixpkgs 仓库中的软件,最佳方案是自己用 Nix 语言写一份打包脚本,给这个软件打一个包,然后把打包定义加入 configuration.nix 中,从而安装到系统上。 关于 NixOS 的软件打包,...
用逆向工程方式给惠普暗影精灵宏按键编写 Linux 驱动
我前段时间换了台新电脑,惠普的暗影精灵 17t-ck000(美版,应该对应的是国内的暗影精灵 7 Plus)。这台电脑好是好,做工优秀,性能强大,就是有一个问题:它在 Linux 下的驱动支持实在是太烂了。 不支持调节风扇转速,你能看到风扇转速,但仅此而已。再加上惠普的默认风扇策略非常激进,即使我开启了 BIOS 中的低温风扇停转功能,它依然在 CPU 温度只有 40 度、显卡空载的情况下转得非常欢快。 其实可以用 NBFC 直接写 EC 寄存器来控制,但在 某次不幸的事故中 当时的配置方案丢失了。 我配置 NBFC 时正在新电脑试用 NixOS。事故发生时新电脑上的 NixOS 被我删掉了,而且当时的配置没上传 GitHub。 过段时间再重新写一遍(咕咕咕) 不支持调整键盘背光颜色,它们在 Windows 下由 OMEN Command Center 软件控制。有时系统崩溃、我长按电源键断电重启时,BIOS 会将键盘背光恢复成默认的五彩斑斓的颜色,此时我只能回到 Windows 进行调节。...