起因
我最近在用 PHP 写一套自己的 VPS 监控系统,包括 VPS 端和显示端。今天下午 3 点,我给监控系统加上了监测 VPS 上服务的运行情况的功能。由于我的 VPS 统一使用 Debian 8
系统,我使用了 service --status-all 作为获取服务运行情况的方式。在测试正常后,我去干其它事了。
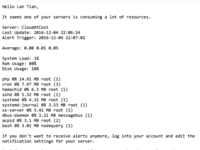
晚上 9 点多,我看到了 NodeQuery 于 7 点给我发的报警邮件,提示我的某台 VPS 内存占用过高。
我打开监控系统一看,这台 VPS 的内存占用达到了 400M / 500M。不仅如此,另一台 VPS 也内存暴涨,达到了 600M / 1G,但因为总内存大没有触发报警。
问题是,这两台 VPS 都只安装了 SS 和锐速,怎么可能占用这么大的内存?我登上其中一台,用 ps -aux 查看进程列表,却发现没有任何进程占用了这么大的内存。
锐速背锅?
我第一时间怀疑的是锐速。众所周知,锐速官方关闭了新用户的购买和下载安装通道,因此我们只能使用破解版的锐速。/serverspeeder/bin/serverSpeeder.sh stop 关闭锐速后,我发现内存占用降了几十M,但仍然居高不下。重启服务器后,内存恢复正常,我便去做其他事了。
结果过了一段时间,我打开我的监控系统,发现这两台 VPS 内存再次开始以 1M / 分钟的速度暴涨。ps -aux 仍然显示一切正常。
肯定是哪里不对了!
排查
由于 ps -aux 正常,我怀疑是系统内核出了问题。但是同样设置的 VPS 我另有一台,运行这个博客,却没有出现这个问题。由于我没有对 MySQL 等进行仔细优化,其内存占用常年在 300M / 500M。
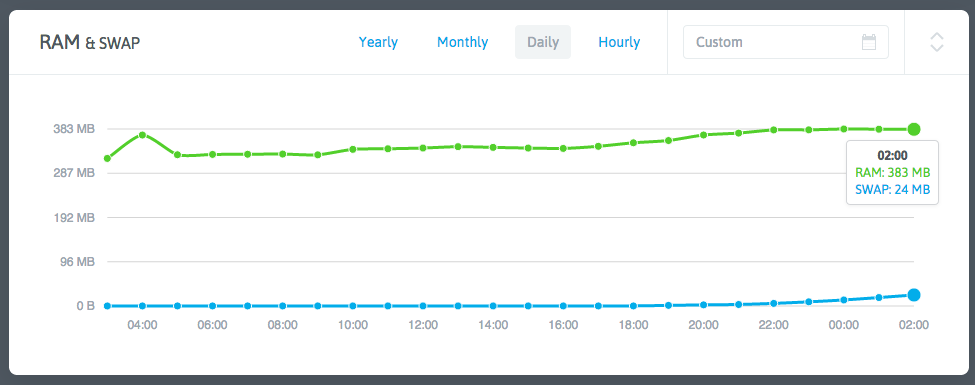
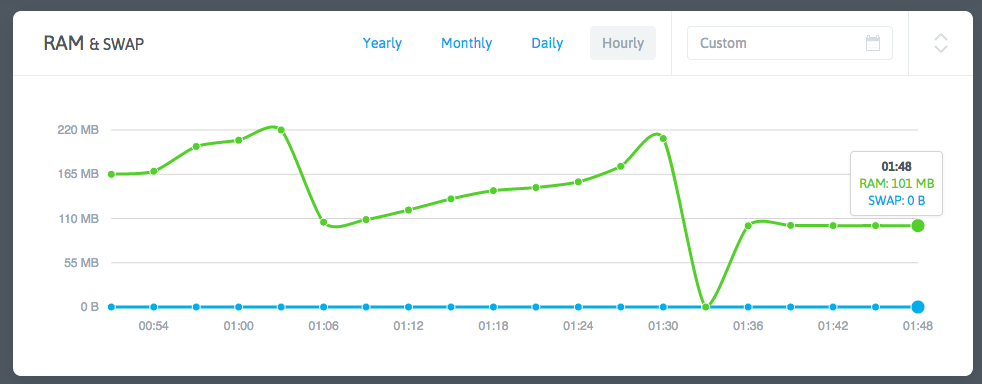
我打开了 NodeQuery,一个 Linux 服务器监控服务商。我的几台 VPS 均安装了它的监控脚本,并都已经运行了很长时间。我点开了出现问题的两台 VPS 发现了下面的图:
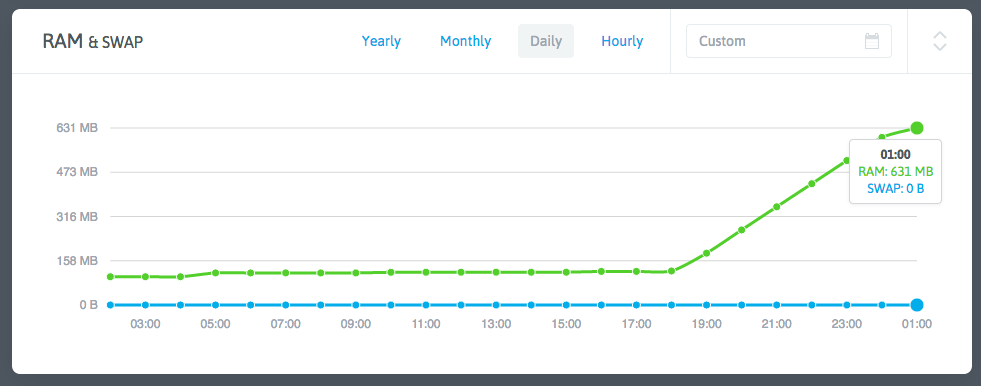
内存占用暴涨的时间是大概 7 小时前,我给监控脚本加上服务监控功能的时候!但是我的监控脚本只是一段简单的 PHP,只是读几个 /proc 里的文件、运行几条常用命令,上传完数据就退出,怎么可能搞出内存泄漏?PHP 也是久经考验的语言了,不可能是它本身的问题。
PHP 可是世界上最好的语言。

我将目光转向了那条命令,service --status-all。我反复执行
service --status-all && free -m,发现并没有什么变化。转念一想,PHP 除了运行这条命令,还干了什么?把这条命令的 stdout 重定向给 PHP,来读取它的输出!
反复执行 service --status-all > /dev/null && free -m,内存占用迅速上涨,每执行一次 1M,和症状相符!
这些内存是谁占的呢?Google 一下,我看到了《记一次内存占用问题的调查过程》,介绍了 Linux 的 Slab 内存机制。有一部分 Slab 内存是可以在内存不足时动态释放的,但是这些内存并不被 free -m 以及我的监控脚本当成可用内存。
但是我 cat /proc/meminfo 了一下,发现 Slab 总内存高达 100M,而当时服务器刚重启完没多久,总内存占用才达到 160M 左右;问题是,这些内存都在 SUnreclaim 项下,意味着这些内存是不可释放的。
反复执行
service --status-all > /dev/null && cat /proc/meminfo | grep SUnreclaim,SUnreclaim
上涨。
于是我做了如下测试:
service --status-all > 1.txt && cat /proc/meminfo | grep SUnreclaim问题持续,说明问题不是 /dev/null 引起。echo 123 > 1.txt && cat /proc/meminfo | grep SUnreclaim问题消失,说明问题非 stdout 重定向引起。- 对于系统上每个服务运行
service [服务名] status > /dev/null && cat /proc/meminfo | grep SUnreclaim问题消失,说明问题产生必须要有service --status-all。
我决定好好研究一下 service 这个东西。Debian 8 把服务都存在 /etc/init.d 里面,所以我 mv /etc/init.d /etc/init.e,service 报错,SUnreclaim 未增加;mkdir /etc/init.d,service 不再报错,但 SUnreclaim 还是不增加。
这说明,问题是由某一个服务的脚本在获取服务运行状态时造成的!
我开始一项一项把服务脚本移回来并测试。当移到 serverSpeeder 时,问题再次产生。把 serverSpeeder 再移走,问题消失。
锐速背锅!
我现在可以确认,/etc/init.d/serverSpeeder 会导致运行 service --status-all 时产生内存泄漏。将服务脚本删除,并在 /etc/rc.local 中手动加入启动命令可以解决问题。
过几天,我会好好研究一下锐速的脚本,找出这个内存泄漏的根源。